
NeuroWhAI의 잡블로그
PlaNet : 구글 딥마인드의 새로운 강화학습 모델 본문
※ 저는 학생 수준도 아니라서 단순히 이런 것이 있더라 하는 글 정도로만 봐주시면 좋겠습니다 ㅎㅎ..
먼저 Two Minute Papers 채널의 영상을 보시겠습니다.
약 한 달 전에 구글에서 PlaNet이라는 강화학습 모델을 공개하였습니다.
과거의 환경 정보만 가지고 미래의 행동과 환경을 예측 수행하여 최선의 행동을 결정한다고 합니다.
계획을 한다는 점에서 Plan이란 단어를 써 Net과 합친 이름인 것 같습니다.
기존 강화학습 알고리즘에 비해 점수가 크게 향상된 건 아닌 듯 하지만 미래를 예측하여 학습하므로 환경과의 상호작용이 50배 줄었다고 합니다.
또한 새로운 게임을 학습할 때 바닥부터 시작하는 것이 아니라 이전 게임에서 학습한 중력, 속도와 같은 공통의 개념을 가진 채로 학습을 이어 진행할 수도 있다고 합니다.
자세한 정보는 구글 AI 블로그에서 보실 수 있고 소스코드도 공개되어 있으므로 세부 구현에 관심이 있으시다면 참고하시기 바랍니다.
아래는 제가 자료를 보고 해석한 것을 간단히 정리한 내용입니다.
틀린 부분이 있을 수 있습니다.
PlaNet은 게임 화면을 이미지 그대로 입력받습니다.
하지만 미래 예측에 이 형식을 그대로 쓰면 여러모로 문제가 많고 효과적이지 못하니 Latent Dynamics Model을 사용합니다.
학습된 모델은 아래처럼 동작합니다.

회색 사다리꼴이 이미지를 잠재 벡터로 바꾸는 인코더이며 초록색 원이 그 히든 벡터입니다.
파란색 사다리꼴은 이 잠재 벡터를 보고 미래 상태에 해당하는 이미지를 예측합니다.
파란색 사각형은 대신 보상을 예측합니다.
이제 위 모델을 이용해서 과거 정보를 보고 미래의 상태와 보상을 예측해야 하는데 예전에 비슷하게 이런 잠재 벡터를 쓰는 World Model이란 녀석이 있었습니다.
잠재 벡터를 통해 미래의 상태를 예측하고 이것을 학습에 사용할 수 있었는데 인코더와 디코더가 무거워서 속도가 느렸습니다.
하지만 PlaNet은 잠재 벡터만 가지고 예측을 수행함으로서 인코더와 디코더의 사용을 배제하였고 실시간 행동 계획이 가능해졌다고 합니다.
그걸 나타낸 그림이 아래에 있습니다.
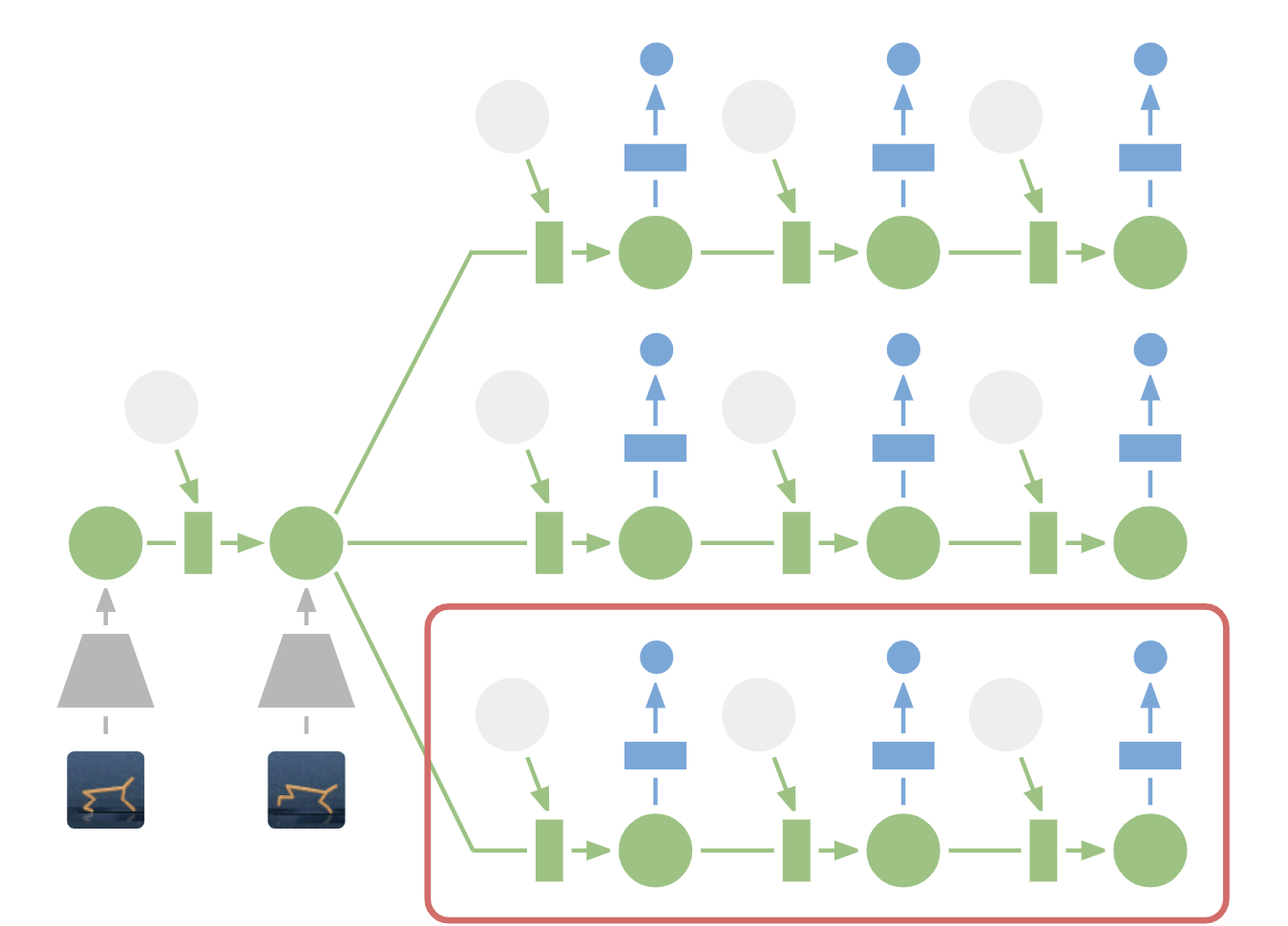
과거 이미지들을 잠재 벡터로 인코딩하는 데에만 인코더가 쓰였고 이후엔 잠재 벡터만 보고 행동을 선택하여 다음 상태와 보상을 예측합니다.
마치 인간이 행동을 계획한다고 일일히 예측한 미래를 그림으로 그리진 않는 것과 비슷하다고 할 수 있겠네요.
이렇게 여러 행동에 대해 깊게 상상하여 보상을 계산할 수 있으니 안정적이고 미래지향적인 행동 선택이 가능할 것 같습니다.
제가 정리한 내용은 이 정도입니다.
틀린 내용은 지적해주시면 정말 감사드리겠습니다.
같이 배웁시다 ㅎㅎ
'자료' 카테고리의 다른 글
| 2019년 4월 19일 강원 동해시 규모 4.3 지진 관련 지진봇 보고 (0) | 2019.04.19 |
|---|---|
| Captura : 오픈소스 사진/동영상 캡처 프로그램 소개 (4) | 2019.04.07 |
| SC-FEGAN : 인공지능을 이용하여 간단한 스케치로 얼굴 사진 편집하기 (0) | 2019.02.24 |
| 2019년 02월 10일 포항 규모 4.1 지진 관련 지진봇 보고 (0) | 2019.02.10 |
| 크롬 'Password Checkup'으로 비밀번호 유출 자동으로 확인하기 (0) | 2019.02.07 |
Comments



