Notice
Recent Posts
Recent Comments
NeuroWhAI의 잡블로그
[TensorFlow] 간단한 분류 모델 본문
넵 헌혈하고 당직서서 컨디션이 똥이지만 열심히(?) 책 따라하고 있습니다.
오늘한건 [털 유무, 날개 유무]라는 입력데이터와 [기타, 포유류, 조류]로 원 핫 인코딩된 출력을 내는 분류 모델입니다.
미리 스포해드리자면 이건 단층 신경망이라 분류가 제대로 안됩니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
import tensorflow as tf
import numpy as np
# [털, 날개]
x_data = np.array(
[[0, 0], [1, 0], [1, 1], [0, 0], [0, 0], [0, 1]]
)
y_data = np.array([
[1, 0, 0], # 기타
[0, 1, 0], # 포유류
[0, 0, 1], # 조류
[1, 0, 0],
[1, 0, 0],
[0, 0, 1],
])
X = tf.placeholder(tf.float32)
Y = tf.placeholder(tf.float32)
W = tf.Variable(tf.random_uniform([2, 3], -1.0, 1.0))
b = tf.Variable(tf.zeros([3]))
L = tf.add(tf.matmul(X, W), b)
L = tf.nn.relu(L)
model = tf.nn.softmax(L)
cost = tf.reduce_mean(-tf.reduce_sum(Y * tf.log(model), axis=1))
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01)
train_op = optimizer.minimize(cost)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for step in range(100):
sess.run(train_op, feed_dict={X: x_data, Y: y_data})
if (step + 1) % 10 == 0:
print(step + 1, sess.run(cost, feed_dict={X: x_data, Y: y_data}))
prediction = tf.argmax(model, axis=1)
target = tf.argmax(Y, axis=1)
print('예측값: ', sess.run(prediction, feed_dict={X: x_data}))
print('실제값: ', sess.run(target, feed_dict={Y: y_data}))
is_correct = tf.equal(prediction, target)
accuracy = tf.reduce_mean(tf.cast(is_correct, tf.float32))
print('정확도: %.2f' % sess.run(accuracy * 100, feed_dict={X: x_data, Y: y_data})
|
이번 코드에선 약간 수학적인게 들어가서 좀 힘들었는데 그나마 이해했습니다.
행렬 개객기...
아 그리고 처음에 분명히 행렬인데 왜 matmul을 안쓰고 '*'를 쓰나 했더니
제가 numpy를 몰라서 그런거였습니다.
numpy의 array는 스칼라를 곱하면 각 요소에 대해 그 곱이 수행됩니다.
np.array([1, 2, 3]) * 2 하면 [2, 4, 6]인 array가 된다는거죠.
활성화 함수로 relu(렐루렐루렐루)를 사용했고 원 핫 인코딩 형식의 출력이므로 더 편하게 보고자 softmax를 사용한것 같습니다.
비용 함수로는 교차 엔트로피를 이용했다는데 공식을 완전히 이해하는건 무리였고
대충 이해해보자면 cost가 최소가 되려면 sum안의 값들이 0에 가까워야하고
그러기위해선 Y나 log(model)의 값이 0에 가까워야하고 (Y는 불변이므로 log만 봄)
그러기위해선 model의 값이 1에 가까워야합니다. log(1)=0이기 때문이죠.
그런데 이렇게 구한 log값을 Y([a, b, c])에 곱해주는 이유는
Y가 원 핫 인코딩된 값이므로 a, b, c 중 값이 1인 요소의 오차만 얻기 위해서 인 것 같습니다
그러고 다음으로 axis=1로 reduce_sum을 해주면 [a, b, c]가 a+b+c가 될텐데
위 과정에서 어차피 셋 중 둘은 0이므로 그냥 필요한 오차값만 뽑아내는 과정이라고 봐도 될 것 같습니다.
마지막으로 reduce_mean으로 오차의 평균을 내게됩니다.
예측값을 계산할때 argmax를 썼는데 axis축에 대해서 가장 큰 값의 인덱스를 반환하는 놈이라고 합니다.
코드에서 axis가 1인 이유는 model이 실제론 여러 입력에 대한 여러 출력이 들어있는 행렬이기 때문이져.
그러니까 argmax([[0, 1, 0], [1, 0, 0], [0, 0, 1]], axis=1)를 하면 [1, 0, 2] 이런식이죠.
즉, 저 함수를 씀으로서 원 핫 인코딩된 결과를 하나의 번호로 대응시키는 역할을 합니다.
[0, 0, 1]이 조류인데 이걸 argmax하면 2가 되므로 조류는 2번에 대응된다라고 할 수 있습니다.
결과 확인이 쉬워지죠.
equal은 그냥 각 요소가 같냐 아니냐를 반환하는거고
cast를 통해서 다르면 0, 같으면 1로 바꾸고 있습니다.
이걸 평균 취하면 전체 정확도가 나오는거죠.
틀린거 지적해주시면 정말 감사드리겠습니다.
혼자하려니까 틀렸는지 안틀렸는지 검증하기 힘드네요.
후아....
그래도 몇개월전에 이 코드를 봤다면 이해하지 못했을거라고 생각하니 뿌듯합니다.
지겹도록 이론 공부만 했던게 그나마 빛을 발하네요.
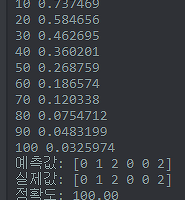
실행결과는 아래와 같습니다.

보시다시피 랜덤으로 W를 초기화하고 있어서 실행할때마다 결과가 다르며
단층 신경망이라 정확도가 떨어집니다.
'개발 및 공부 > 라이브러리&프레임워크' 카테고리의 다른 글
| [TensorFlow] 텐서보드 적용 (7) | 2018.01.17 |
|---|---|
| [TensorFlow] 간단한 분류 모델 - 심층 신경망 (0) | 2018.01.10 |
| [Tokio] Rust 비동기 입출력 라이브러리 (0) | 2018.01.07 |
| [TensorFlow] 선형 회귀 (0) | 2018.01.07 |
| [Rust] bytes::Bytes (0) | 2018.01.06 |
Comments
'개발 및 공부/라이브러리&프레임워크' Related Articles
more