Notice
Recent Posts
Recent Comments
NeuroWhAI의 잡블로그
[TensorFlow] 텐서보드 적용 본문
어제 했는데 오늘 쓰네요 ㅋㅋ
어제는 텐서보드를 사용해서 이전에 만든 모델을 텐서보드로 볼 수 있게 코드를 수정했습니다.
아, 또 학습데이터를 아래처럼 외부 파일로 분리시켰습니다.
data.csv
0, 0, 1, 0, 0
1, 0, 0, 1, 0
1, 1, 0, 0, 1
0, 0, 1, 0, 0
0, 0, 1, 0, 0
0, 1, 0, 0, 1
첫 두열이 x_data고 나머지가 y_data입니다.
main.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
|
import tensorflow as tf
import numpy as np
data = np.loadtxt('./data.csv', delimiter=',', unpack=True, dtype='float32')
x_data = np.transpose(data[0:2])
y_data = np.transpose(data[2:])
global_step = tf.Variable(0, trainable=False, name='global_step')
X = tf.placeholder(tf.float32)
Y = tf.placeholder(tf.float32)
with tf.name_scope('layer1'):
W1 = tf.Variable(tf.random_uniform([2, 10], -1.0, 1.0), name='W1')
L1 = tf.nn.relu(tf.matmul(X, W1))
with tf.name_scope('layer2'):
W2 = tf.Variable(tf.random_uniform([10, 20], -1.0, 1.0), name='W2')
L2 = tf.nn.relu(tf.matmul(L1, W2))
with tf.name_scope('output'):
W3 = tf.Variable(tf.random_uniform([20, 3], -1.0, 1.0), name='W3')
model = tf.matmul(L2, W3)
with tf.name_scope('optimizer'):
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(
labels=Y, logits=model
))
optimizer = tf.train.AdamOptimizer(learning_rate=0.01)
train_op = optimizer.minimize(cost, global_step=global_step)
tf.summary.scalar('cost', cost)
with tf.Session() as sess:
saver = tf.train.Saver(tf.global_variables())
ckpt = tf.train.get_checkpoint_state('./model')
if ckpt and tf.train.checkpoint_exists(ckpt.model_checkpoint_path):
saver.restore(sess, ckpt.model_checkpoint_path)
else:
sess.run(tf.global_variables_initializer())
merged = tf.summary.merge_all()
writer = tf.summary.FileWriter('./logs', sess.graph)
for step in range(100):
sess.run(train_op, feed_dict={X: x_data, Y: y_data})
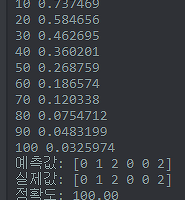
print('Step: %d, ' % sess.run(global_step),
'Cost: %.3f' % sess.run(cost, feed_dict={X: x_data, Y: y_data}))
summary = sess.run(merged, feed_dict={X: x_data, Y: y_data})
writer.add_summary(summary, global_step=sess.run(global_step))
saver.save(sess, './model/dnn.ckpt', global_step=global_step)
prediction = tf.argmax(model, 1)
target = tf.argmax(Y, 1)
print('예측값:', sess.run(prediction, feed_dict={X: x_data}))
print('실제값:', sess.run(target, feed_dict={Y: y_data}))
is_correct = tf.equal(prediction, target)
accuracy = tf.reduce_mean(tf.cast(is_correct, tf.float32))
print('정확도: %.2f' % sess.run(accuracy * 100, feed_dict={X: x_data, Y: y_data}))
|
cs |
이번에도 바뀐 부분만 해설!
학습 데이터를 외부로 뺐으므로 불러와야합니다.
numpy의 loadtxt로 쉽게 불러올 수 있었습니다.
unpack 매개변수를 True로 하면 데이터가 회전하게 됩니다.
그러니까 행렬이 바뀐답니다.
[
[1, 2, 3],
[4, 5, 6]
]
이랬다면
[
[1, 4],
[2, 5],
[3, 6]
]
이렇게 되는거죠!
왜 이러냐면 데이터를 쉽게 분리하기 위해서입니다!
그 밑을 보시면 data[0:2]처럼 슬라이싱으로 쉽게 X 데이터와 Y 데이터를 분리할 수 있죠.
그런다음 np의 transpose 함수로 다시 행렬을 바꿔줍니다.
이전 글에서 global_step을 설명했나 모르겠네요.
이 값은 학습 횟수를 담을 변수인데 학습과는 상관이 없으므로 trainable이 False입니다.
optimizer의 minimize함수에 global_step 매개변수로 이 변수를 넘겨주면
최적화가 한번 실행될때마다 이 변수가 1 증가한다고 합니다.
그 다음은 신경망을 만들고있는데 텐서보드에서 좀 쉽게 보기위해서
각 레이어를 tf.name_scope로 그룹화하고 있습니다.
tf.summary.scalar('cost', cost)는 통계에 cost라는 이름으로 cost 변수를 넣겠다는 선언입니다.
텐서플로에 tf.Variable이 있다면 텐서보드엔 tf.summary가 있다는 느낌으로 보면 될것같습니다.
Saver를 사용해서 모델을 저장하고 다시 불러오는건 마지막에 설명하겠습니다.
tf.summary.merge_all()은 텐서플로에 global_variables_initializer()가 있다면 텐서보드엔 이게 있다...는 느낌입니다.
글로벌 통계 요소들을 전부 모아줍니다.
이 함수로 받은 merged를 세션에서 실행할때마다 데이터를 한번 기록하는거라 보면 될것같습니다.
FileWriter는 기록한 통계를 파일로 내보내줍니다.
생성할때 세션의 graph를 넣어주면 텐서보드에서 모델을 시각화해서 볼 수 있습니다.
학습을 100번 하는데 할때마다
merged 연산을 수행해서 추적하는 변수의 값을 기록하고
그렇게 만든 통계 데이터를 writer를 통해 파일에 추가로 기록합니다.
마지막으로 모델 재사용입니다.
다시 Saver가 있던 라인으로 돌아가서....
tf.Train.Saver로 모델을 저장하는 객체를 만듭니다.
모든 변수를 저장하도록 tf.global_variables()를 매개변수로 넣었습니다.
지정한 경로에서 체크포인트 파일을 불러와서 모델의 경로를 알아낸다음
존재하면 saver.restore(...)로 모델을 복구합니다.
이때는 당연히 global_variables_initializer()를 수행할 필요가 없습니다.
학습을 끝내고 저장하려면
saver.save(...)를 호출합니다.
global_step 매개변수를 설정해주면 이 값이 파일이름에 붙는다고 합니다.
끝!
다음은 가브릴드롭아웃이던데... 벌써...?
'개발 및 공부 > 라이브러리&프레임워크' 카테고리의 다른 글
| [TensorFlow] MNIST CNN(합성곱 신경망)으로 학습하기 (1) | 2018.01.20 |
|---|---|
| [TensorFlow] MNIST 수행 결과 matplotlib로 이미지와 함께 출력 (1) | 2018.01.19 |
| [TensorFlow] 간단한 분류 모델 - 심층 신경망 (0) | 2018.01.10 |
| [TensorFlow] 간단한 분류 모델 (0) | 2018.01.09 |
| [Tokio] Rust 비동기 입출력 라이브러리 (0) | 2018.01.07 |
Comments
'개발 및 공부/라이브러리&프레임워크' Related Articles
more